How we write rebuttals
By Devi Parikh, Dhruv Batra, Stefan Lee

We frequently find ourselves giving the same advice to different students on how to write rebuttals. So we thought we’d write it up. Our experience is with AI conferences (e.g., CVPR, ECCV, ICCV, NeurIPS, ICLR, EMNLP).The core guiding principle is that the rebuttal should be thorough, direct, and easy for the Reviewers and Area Chair (RACs) to follow.
Why do we write rebuttals?
In a phrase — to clarify and convince. Science is a deliberative process, and rebuttals are simply a stage in that process.
Bill Freeman gave an excellent talk at the “Good Citizen of CVPR” panel at CVPR18. He talked about the idealized image of the peer review process that new members of a research community often hold — they imagine scholars, with plenty of time on their hands, gathered around a quiet space carefully pouring over the nuances of their work.
The reality, Bill describes, is more like a large crowded marketplace. It’s messy and it’s chaotic; different actors in the process are trying to achieve different goals, each operating under limited time and attention-spans, partial information, while juggling multiple responsibilities.
With this in mind, it is important to note who we write rebuttals for and what our goal is.
We write rebuttals for two different audiences
- The reviewers, who have read your paper (to varying degrees), but may have forgotten some of the details or didn’t understand them in the first place.
- The AC, who is likely even less familiar with your work, and a good guiding principle is to assume that all they will read is the set of reviews and the rebuttal.
Our goals are
- For the reviewers: clarify doubts, answer questions, correct misunderstandings, push back on mischaracterizations, and make a good-faith effort to incorporate feedback and improve your work.
- For the AC: convince them that you have made a good-faith effort, present a representative summary of the reviews, help them understand if the reviewer concerns were addressed, call out bad-faith reviewing, and ultimately, help them make a decision.
In our experience, most new members of the research community focus on (1), but ignore (2).
An imperfect but useful metaphor for rebuttals is debate competitions. Yes, we are trying to convince our opponent (and this is where the metaphor is imperfect; reviewers are not our opponents, but hang with us). But more importantly, we are trying to convince the judges, who will ultimately be making the decisions. Thus, all else being equal, it is more important to convince the judges of your arguments than change your opponents’ minds.
We provide concrete recommendations below, but a good short-hand is the following — would a neutral third-party be able to tell if the reviewer concerns were addressed purely based on your rebuttal (without reading the paper or the reviews again)?
Our Process.
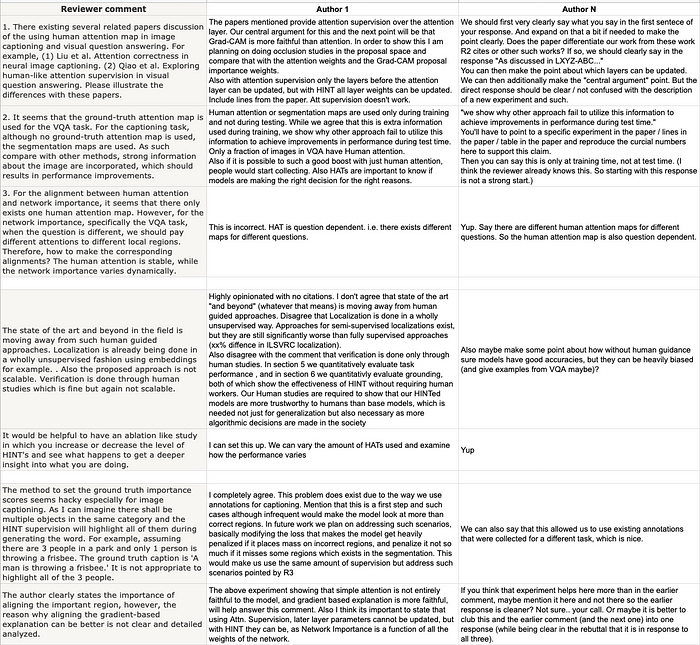
- Itemize reviewer comments. We use a handy spreadsheet to organize individual comments/questions/concerns raised by each reviewer. Laying everything out in the same place helps identify common concerns and keeps us from missing anything accidentally. Do this ASAP to identify any necessary new experiments (if the venue allows it) or analysis early.
- Brain dump possible responses. The sheet has a column for each author to reply to each reviewer comment. Dump your thoughts here in rough text without regard for style or length. Being convincing and concise is a subtractive process.
- Write a draft rebuttal. Turn your consensus in the sheet into concrete responses in a rebuttal draft. Write concisely but don’t worry about space. Cover every point and trim / prioritize them later.
- Review and revise. Reread the initial reviews and your sheet to make sure everything has been addressed. Prioritize major concerns and start working towards meeting space limitations.
Example set of initial responses from authors is shown below. You’ll see more polished snippets of some of these responses through the rest of this post
As for putting together the rebuttal itself, below is a list of tips and principles we follow and believe are effective. Others likely have their own.
Tip 1. Start positive. Provide a summary of the reviews, highlighting positive things that reviewers said about your work. Rebuttals focus mostly on responding to perceived negatives, don’t let RACs forget about the strengths along the way.



Tip 2. Order matters. Start with the biggest concerns that you have good answers for and work your way to less clear-cut responses and minor points.
Tip 3. Let reviewers speak for themselves, then respond directly. Quote the core of the reviewer’s question or concern concisely and completely. Then before saying anything else, respond to it directly. And then give details, describe context, or explain your position.
- “Are these averaged across multiple runs?”:
“Yes, we averaged across 5 random seeds.” - “Are the segmentation masks used during training?”:
“No, they are only used to evaluate our results.” - “So overall, the proposed approach needs more human annotations than the baseline.”:
“Not quite. While the first few iterations of our approach need a human in the loop more often, as we collect more data, our approach relies on humans less than the baseline. For typical dataset sizes, we use fewer annotations overall. E.g., for GNART20 with 10k images, our approach uses 2.4k human annotations while the baseline uses 2.8k” - “Does your baseline match the one reported by Smith et al. at CVPR last year [43]?”:
“Almost. The is a 0.1% difference in performance between [43]’s publicly available code and what is reported in [43]. Our baseline matches the former.” - “Did you evaluate on realistic environments?”:
“We disagree with the question’s premise. While these environments are simulated, they are highly photorealistic.” - “Why did you not compare to GMAP?“
“GMAP is prohibitively expensive in our setting. Our environments have a significantly larger state-space (10k) than BRIE (20) which has been used to evaluate GMAP thus far. Back-of-the-envelope calculations suggest it would take 128 GPUS for 3 months to evaluate GMAP.”
Tip 4. Be conversational. Notice the conversational nature of the example responses above. It makes it easier for RACs to follow, and the responses are less likely to be perceived as being combative.
Tip 5. Respond to the intent of the questions. Don’t feel trapped to only discuss the quoted concern — also address the intent of the comment. For example, “Why didn’t you evaluate on GLORP3?” may generally be calling your experiments into question. Answer, but then point out that you’ve already evaluated on X,Y, and Z which should be sufficient! Note that it is useful for other RACs to be reminded of your extensive experimental evaluation. A first glance at a reviewer comment suggesting otherwise could leave a false impression.

Tip 6. Don’t be afraid of emphasis. “Row 2 in Table 4 shows exactly that.” “We do NOT need a human-in-the-loop at test time.” Notice that many of the responses above are not just direct, but also have emphasis (in tone if not formatting of text).

Tip 7. Feel free to set the stage. If it seems like all reviewers missed a central point, a concise, crisp recap of the main point could help.
Tip 8. Keep things self-contained. Assume RACs don’t remember much about your paper and that they likely won’t read it again in detail. Re-introduce any acronyms, remind them of relevant details of an experimental setup. Notice that all the responses above likely make sense to you even though you may be unfamiliar with the papers (and in some cases the names and details are made up).
Tip 9. But get credit for details you already included. That said, if something a reviewer asked for was already in the paper, say so. Give them line/Table/Figure numbers, and then restate it in the rebuttal. The references back to the main paper are to establish credibility with all RACs that the paper was not lacking important details. (They are not necessarily to have RACs go back and look at the paper.)
[R1: baseline that retrieves images from caption]
As described in L341, 746, 772, round 0 is the caption. Thus the round 0 point in Fig 4a is the caption-based image retrieval baseline. At the best-performing round, RL-Full-QAf achieves ~3% percentile (~285 absolute rank) improvement over RL-Full-QAf round 0.
Tip 10. Consolidate common concerns. Save space by responding to multiple reviewers at once if they share related concerns.

Tip 11. Color-code reviewers. Notice above the trick to color-code reviewers. Make it as easy as possible for reviewers to spot responses that are relevant to them — even when things are merged or not in reviewer order.
Tip 12. Stats speak louder than words. Rather than argue with RACs, give them data/stats to back your claim up. These can be statistics/analysis of your data or results. Or the results of additional experiments you run to respond to their concern (if allowed by the venue). Every time you find yourself having a different opinion than the reviewer, ask if you can establish that with data. You can always provide the intuitive arguments after you’ve settled the issue with data.
Tip 13. Don’t promise, do. Instead of saying “We will discuss Singh et al. in the paper.”, provide a discussion in the rebuttal. Instead of saying “We will explain what D_{RT} stands for in the paper”, explain what it stands for in the rebuttal. And then also add that you will add it to the paper. It makes it significantly easier for RACs to trust that you will make the promised changes.

Tip 14. Be receptive and reasonable. Most RACs will appreciate it. Plus, it is just the better thing to do — these are your colleagues! :)

Likewise, instead of arguing why a reviewer’s suggestion might not work, try it and see if it works. Maybe it will!


Tip 15. Be transparent. Reviewers hinted at an additional experiment but the venue doesn’t allow it? Say so. They asked about intuitions about a trend but you don’t have any? Say that you’ve thought about it but don’t have any good ideas, and will continue to investigate it. Don’t have enough GPUs to run the experiment they asked for? Say so.

Tip 16. Shine a spotlight on reviewers acting in bad-faith. In some circumstances, a reviewer may not be adhering to reviewing best practices or may not have taken the reviewing role seriously. It can be important to make sure the other RACs realize this and appropriately discount their review. Pointing out unreasonable or unsubstantiated comments and referencing other reviewers that disagree can help. This can also include confidential comments to the AC (where applicable).


Tip 17. Acknowledge reviewer efforts. On the other hand, if a reviewer goes above and beyond to be constructive, thank them for it. Typo list? Thank you. Pointers to relevant work? Thank you. Detailed musings about future work? Thank you. Add at least a short blurb acknowledging these things!
Tip 18. Don’t forget the humans on the other end. Keep in mind that this is not just a scientific but a sociopolitical interaction with other humans :) So decide whether you’d like to be argumentative and risk your reviewer taking a strong stand against the paper, or if you’d like to work towards a common ground. Finding points where you do agree with the reviewer and acknowledging them can help with the latter.
We hope this was helpful, and happy rebutting :)
